We ❤️ Open Source
A community education resource
Build a local AI co-pilot using IBM Granite Code, Ollama, and Continue
Discover how to adopt AI co-pilot tools in an enterprise setting with open source software.

In this two-part tutorial, I will show how to use a collection of open source components to run a feature-rich developer co-pilot in Visual Studio Code while meeting data privacy, licensing, and cost challenges that are common to enterprise users. The setup is powered by local large language models (LLMs) with IBM’s open source LLM family, Granite Code. All components run on a developer’s workstation and have business-friendly licensing. For the quick version, just jump to the TL;DR end-to-end setup script or check out part two of this tutorial: 4 ways to extend your local AI co-pilot framework.
The developer world is quickly becoming the best place for AI developers to drink our own champagne with the promise of generative AI to accelerate our own work. There are numerous excellent AI co-pilot tools out there in the market (GitHub Copilot, tabnine, Sourcegraph Cody, watsonx Code Assistant to name just a few). These tools offer in-editor chatbots, code completion, code explanation, test generation, auto-documentation, and a host of other developer-centric tools. Unfortunately, for many of us, these tools sit out of reach behind corporate data privacy policies (yes, we can access watsonx Code Assistant here at IBM, but the rest are not available.)
There are three main barriers to adopting these tools in an enterprise setting:
- Data privacy: Many corporations have privacy regulations that prohibit sending internal code or data to third party services.
- Generated material licensing: Many models, even those with permissive usage licenses, do not disclose their training data and therefore may produce output that is derived from training material with licensing restrictions.
- Cost: Many of these tools are paid solutions which require investment by the organization. For larger organizations, this would often include paid support and maintenance contracts which can be extremely costly and slow to negotiate.
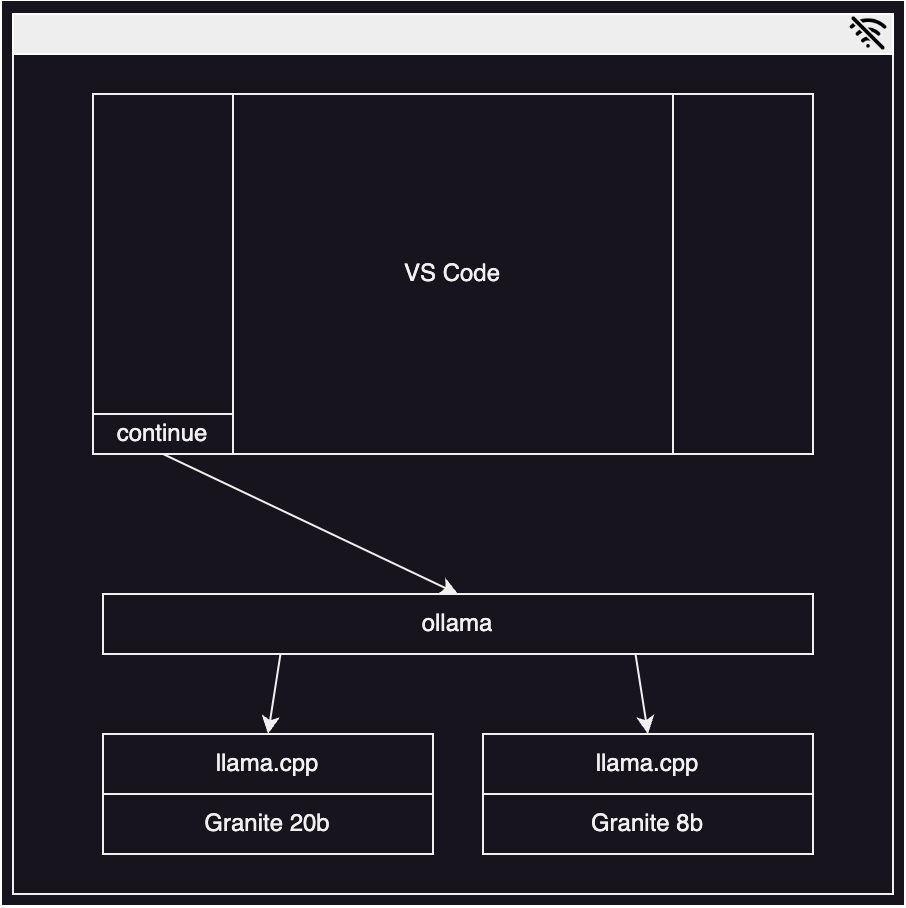
In this two-part tutorial, I will show how I solved all of these problems using IBM’s Granite Code Models, Ollama, Visual Studio Code, and Continue, as well as how to extend the framework to fit your personal needs in the second part.
Step 1. Install ollama
The first problem to solve is avoiding the need to send code to a remote service. One of the most widely used tools in the AI world right now is Ollama, which wraps the underlying model serving project llama.cpp.
The ollama CLI makes it seamless to run LLMs on a developer’s workstation, using the OpenAI API with the /completions and /chat/completions endpoints. Users can take advantage of available GPU resources and offload to CPU where needed.
My workstation is a MacBook Pro with an Apple M3 Max and 64GB of shared memory, which means I have roughly 45GB of usable VRAM to run models with! Users with less powerful hardware can still use ollama with smaller models or models with higher levels of quantization.
On a MacOS workstation, the simplest way to install ollama is to use homebrew:
brew install ollamaYou can also download ollama directly for Mac, Linux, and Windows (preview).
Once you have ollama installed, you need to boot the central server:
ollama serveIMPORTANT: This is a long-running process. You’ll want to run it in a separate terminal window so that your co-pilot can connect to it. Alternately, you can use a separate solution like my ollama-bar project, which provides a macOS menu bar app for managing the server (see Managing ollama serve for the story behind ollama-bar).
Step 2. Fetch the Granite models
The second problem to solve is choosing a model that gives high-quality output and was trained on enterprise safe data. There are numerous good code models available on the ollama library and huggingface.
According to section 2 of this paper published by IBM Research titled, “Granite Code Models: A Family of Open Foundation Models for Code Intelligence,” the IBM Granite Code models meticulously curated their training data to ensure all training code carried enterprise-friendly licenses and all text did not contain any hate, abuse, or profanity. Since generated material licensing is one of the primary concerns I’ve already identified, and since I work for IBM, I chose this family of models for my own use.
Granite Code comes in a wide range of sizes to fit your workstation’s available resources. Generally, the bigger the model, the better the results, but the more resources it will require and the slower it’ll be. I chose the 20b option as my starting point for chat and the 8b option for code generation. Ollama offers a convenient pull feature to download models:
ollama pull granite-code:20b
ollama pull granite-code:8bA NOTE ON CONTEXT LENGTHS: Back to the paper (section 3) I referenced earlier, the various sizes of Granite Code models come with different context lengths. Longer context lengths will allow your co-pilot to process larger pieces of code.
Step 3. Set up Continue
With the Granite models available and ollama running, it’s time to start using them in your editor. The first step is to get Continue installed into Visual Studio Code. This can be done with a quick command line call:
code --install-extension continue.continueAlternately, you can install continue using the extensions tab in VS Code:
- Open the Extensions tab.
- Search for “continue.”
- Click the Install button.
Next, you need to configure Continue to use your Granite models with Ollama.
- Open the command pallette (Press Ctrl/Cmd+Shift+P)
- Select Continue: Open config.json.
This will open the central config file ($HOME/.continue/config.json by default) in your editor. To enable your ollama Granite models, you’ll need to edit two sections:
models: This will set up the model to use for chat and long-form prompts (for example,explain). Here I use the larger20bmodel which will be slower but able to process more context and give richer results.
"models": [
{
"title": "Granite Code 20b",
"provider": "ollama",
"model": "granite-code:20b"
}
],tabAutocompleteModel: This will set up the model to use for inline completions. Here I use the smaller8bmodel which will run faster and be able to produce completions quickly enough that they’re useful to me when writing code.
"tabAutocompleteModel": {
"title": "Granite Code 8b",
"provider": "ollama",
"model": "granite-code:8b"
},Step 4. Give your co-pilot a try
With continue installed and Granite running, you should be ready to try out your new local AI co-pilot. Click the new continue icon in your sidebar:
You can follow the usage guidelines in the documentation.
TLDR
For the impatient, here’s the end-to-end setup script:
# Install ollama
brew install ollama
# Start the ollama server in the background
ollama serve &
# Download IBM Granite Code models
ollama pull granite-code:20b
ollama pull granite-code:8b
# Install continue in VS Code
code --install-extension continue.continue
# Configure continue to use the models
printf %s\\n "{\"models\":[{\"title\":\"Granite Code 20b\",\"provider\":\"ollama\",\"model\":\"granite-code:20b\"}],\"customCommands\":[{\"name\":\"test\",\"prompt\":\"{{{ input }}}\n\nWrite a comprehensive set of unit tests for the selected code. It should setup, run tests that check for correctness including important edge cases, and teardown. Ensure that the tests are complete and sophisticated. Give the tests just as chat output, don't edit any file.\",\"description\":\"Write unit tests for highlighted code\"}],\"tabAutocompleteModel\":{\"title\":\"Granite Code 8b\",\"provider\":\"ollama\",\"model\":\"granite-code:8b\"},\"allowAnonymousTelemetry\":false,\"embeddingsProvider\":{\"provider\":\"transformers.js\"}}" > $HOME/.continue/config.jsonConclusion
I’ve demonstrated how to solve the problems of cost, licensing, and data privacy in adopting AI co-pilot tools in an enterprise setting using IBM’s Granite Code Models, Ollama, Visual Studio Code, and Continue. With this setup, developers can effectively avoid the common obstacles to adopting AI-powered development tools in enterprise environments, including data privacy concerns, licensing restrictions, and cost barriers. Using local LLMs offers a unique opportunity for developers to harness the capabilities of AI-driven code completion, refactoring, and analysis while ensuring the integrity and security of their codebase.
Next steps
- Explore more articles and tutorials about watsonx on IBM Developer.
- Read part two of this tutorial series: 4 ways to extend your local AI co-pilot framework.
- Read more from We Love Open Source: Getting started with Llamafile tutorial
This article is adapted from “Build a local AI co-pilot using IBM Granite Code, Ollama, and Continue” by Gabe Goodhart, and is republished with permission from the author.

The opinions expressed on this website are those of each author, not of the author's employer or All Things Open/We Love Open Source.