We ❤️ Open Source
A community education resource
Harness the power of large language models part 1: Getting started with Ollama
Explore using Ollama and open source AI on your local system.

Everywhere you look, someone is talking or writing about artificial intelligence. I have been keenly interested in the topic since my graduate school days in the 1990s. I have used ChatGPT, Microsoft Copilot, Claude, Stable Diffusion, and other AI software to experiment with how this technology works and satisfy my innate curiosity.
I discovered Ollama. Developed by Meta, it is an open source large language model (LLM) that can run locally on Linux, MacOS, and Microsoft Windows. There is a great deal of concern that while using LLMs in the cloud, your data is being scraped and reused by one of the major technology companies. Ollama is open source and has an MIT license. Since Ollama runs locally, there is no danger that your work could end up in someone else’s LLM.
The Ollama website proclaims, “Get up and running with Large Language Models.” That invitation was all I needed to get started. Open a terminal on Linux and enter the following to install Ollama:
curl -fsSL https://ollama.com/install.sh | shThe project lists all the models that you can use, and I chose the first one in the list, Llama3.1. Installation is easy, and it did not take long to install the Llama3.1 model. I followed the instructions and, in the terminal, entered the following command:
$ ollama run llama3.1The model began to install, which took a couple of minutes. This could vary depending on your CPU and internet connection. I have an Intel i7 with 64 GB RAM and a robust internet connection. Once the model was downloaded, I was prompted to ‘talk‘ with the LLM. I decided to ask a question about the history of my alma mater, St. Bonaventure University. I entered the following commands:
$ ollama run llama3.1
>>>What is the history of St. Bonaventure University?The results were good but somewhat inaccurate. “St. Bonaventure University is a private Franciscan university located in Olean, New York. The institution was founded by the Diocese of Buffalo and has a rich history dating back to 1856.” St. Bonaventure is located near Olean, New York, and it is in the Diocese of Buffalo, but it was founded in 1858. I asked the model to name some famous St. Bonaventure alumni; more inaccuracies were comic. Bob Lanier was a famous alumnus but Danny Ainge was not.
Read more: Getting started with Llamafile tutorial
Trying Ollama on different systems
The results are rendered in MarkDown, which is a real plus. I also knew that having a GPU would render the results much quicker. I wanted to install Ollama on my M2 MacBook Air which I soon did. I followed the much easier directions: Download the Ollama-darwin.zip, unzip the archive, and double-click the Ollama icon. The program is installed in the MacBook’s Application folder. When the program is launched, it directs me to the Mac Terminal app, where I can enter the same commands I had entered on my Linux computer.
Unsurprisingly, Ollama uses a great deal of processing power, which is lessened if you run it on a computer with a GPU. My Intel NUC 11 is a very powerful desktop computer with quad-core 11th Gen Intel Core i7-1165G7, 64 gigabytes of RAM, and a robust connection to the internet to download additional models. I posed similar questions to the Llama3.1 model first on the Intel running Linux and then on the M2 MacBook Air running MacOS.
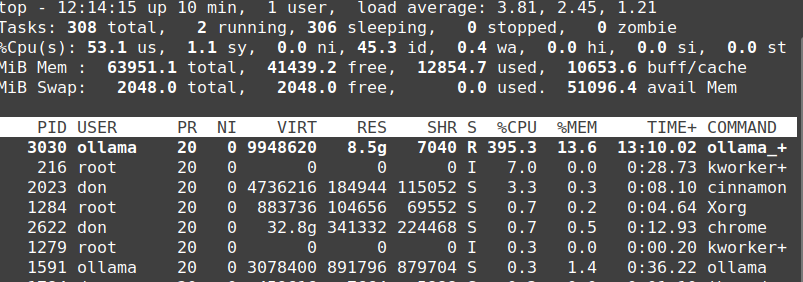
You can see the CPU utilization below on my Linux desktop. It’s pegged, and the output from the model is slow at an approximate rate of 50 words per minute. Contrast that with the M2 MacBook, which has a GPU with a CPU utilization of approximately 6.9% and words per minute faster than I could read.
Creating Python code with Ollama
While Ollama Llama3.1 might not excel at history recall, it does very well when asked to create Python code. I entered a prompt to create Python code to create a circle without specifying how to accomplish the task. It rendered the code shown below. I had to install the pygame module, which is not on my system.
$ sudo apt install python3-pygame
# Python Game Development
import pygame
from pygame.locals import *
# Initialize the pygame modules
pygame.init()
# Create a 640x480 size screen surface
screen = pygame.display.set_mode((640, 480))
# Define some colors for easy reference
WHITE = (255, 255, 255)
RED = (255, 0, 0)
while True:
# Handle events
for event in pygame.event.get():
if event.type == QUIT or (event.type == KEYDOWN and event.key ==
K_ESCAPE):
pygame.quit()
quit()
screen.fill(WHITE) # Fill the background with white color
# Drawing a circle on the screen at position (250, 200), radius 100
pygame.draw.circle(screen, RED, (250, 200), 100)
# Update the full display Surface to the screen
pygame.display.flip()I copied the code into VSCodium and ran it. You can see the results below.

As I continue experimenting with Ollama and other open source LLMs, I’m struck by the significance of this shift toward local, user-controlled AI. No longer are we forced to rely on cloud-based services that may collect our data without our knowledge or consent. With Ollama and similar projects, individuals can harness the power of language models while maintaining complete ownership over their work and personal information. This newfound autonomy is a crucial step forward for AI development and I’m eager to see where it takes us.
More from We Love Open Source
- Read part two of this tutorial series: Working with Ollama
- 4 ways to extend your local AI co-pilot framework
- Building a RAG system with Google’s Gemma, Hugging Face, and MongoDB
This article is adapted from “Breaking Free from the Cloud: Exploring the Benefits of Local,Open-Source AI with Ollama” by Don Watkins, and is republished with permission from the author.

The opinions expressed on this website are those of each author, not of the author's employer or All Things Open/We Love Open Source.